Motivation
[alk: Update from Dec 2024] Wondering how to update this document from beginning of 2000-x I am choosing to keep this original motivation writeup just below. Do keep in mind that referenced glibc versions are now long obsolete. And amount of time per malloc call is far from correct anymore. And the description is for 32-bit computers. Still, I am choosing to keep this text intact, to help people see where tcmalloc came from. "I" below refers to original author: Sanjay. See at the end of this paragraph for some commentary relevant for today.
TCMalloc is faster than the glibc 2.3 malloc (available as a separate library called ptmalloc2) and other mallocs that I have tested. ptmalloc2 takes approximately 300 nanoseconds to execute a malloc/free pair on a 2.8 GHz P4 (for small objects). The TCMalloc implementation takes approximately 50 nanoseconds for the same operation pair. Speed is important for a malloc implementation because if malloc is not fast enough, application writers are inclined to write their own custom free lists on top of malloc. This can lead to extra complexity, and more memory usage unless the application writer is very careful to appropriately size the free lists and scavenge idle objects out of the free list.
TCMalloc also reduces lock contention for multi-threaded programs. For small objects, there is virtually zero contention. For large objects, TCMalloc tries to use fine grained and efficient spinlocks. ptmalloc2 also reduces lock contention by using per-thread arenas but there is a big problem with ptmalloc2’s use of per-thread arenas. In ptmalloc2 memory can never move from one arena to another. This can lead to huge amounts of wasted space. For example, in one Google application, the first phase would allocate approximately 300MB of memory for its URL canonicalization data structures. When the first phase finished, a second phase would be started in the same address space. If this second phase was assigned a different arena than the one used by the first phase, this phase would not reuse any of the memory left after the first phase and would add another 300MB to the address space. Similar memory blowup problems were also noticed in other applications.
Another benefit of TCMalloc is space-efficient representation of small
objects. For example, N 8-byte objects can be allocated while using
space approximately 8N * 1.01 bytes. I.e., a one-percent space
overhead. ptmalloc2 uses a four-byte header for each object and (I
think) rounds up the size to a multiple of 8 bytes and ends up using
16N bytes.
[alk: Update from Dec 2024] tcmalloc (now gperftools) has evolved a lot over last 20-ish years. Back then it was one of the first production-grade malloc that used per-thread caching. This days per-thread (or even per-cpu) caching is widespread. Typical C++ programs tend to allocate and free memory somewhat frequently and those small allocations are generally kept fast and avoid any locks (in most cases). Most of gperftools evolution was on getting those common cases even cheaper. Others improved too. glibc, while still being somewhat slower than gperftools, is a lot faster than it was and also avoids locks in many of those common case allocations.
gperftools on modern systems with efficient "native" thread-local storage access (i.e. GNU/Linux, most BSDs, even Windows, but, notably, not OSX) takes just a couple dozen cheap instructions for allocation or deallocation, which is better than most competition. We’re talking in the ballpark of just a couple nanoseconds per operation on modern fast out-of-order CPUs in this fast-path case (all caches are hot etc). I.e. compare to mid-tens of nanos per malloc/free pair 20 years ago (!)
Also, the reader should be aware that another descendant of the original tcmalloc is now available at https://github.com/google/tcmalloc (I call it "abseil tcmalloc" due to it’s hard dependency on abseil). Its main feature is efficient per-cpu caches (but it needs RSEQ support from fairly recent Linux kernels).
Another direction of evolution, particularly at Google, was increasing focus on helping diagnose or prevent production problems related to dynamic memory allocation. So there is debug version of tcmalloc with some relatively lightweight checking against common bugs (like double-free). So there is heap sampling that has low enough overhead to be always enabled. There are relatively comprehensive statistics available and more. "abseil tcmalloc" is doing even better than gperftools in this regard.
Usage
To use TCMalloc, just link TCMalloc into your application via the "-ltcmalloc" linker flag.
You can use TCMalloc in applications you didn’t compile yourself, by using LD_PRELOAD:
% LD_PRELOAD="/usr/lib/libtcmalloc.so"
TCMalloc includes a heap profiler as well.
If you’d rather link in a version of TCMalloc that does not include
the heap profiler (perhaps to reduce binary size for a static binary),
you can link in libtcmalloc_minimal instead.
Overview
TCMalloc assigns each thread a thread-local cache. Small allocations are satisfied from the thread-local cache. Objects are moved from central data structures into a thread-local cache as needed, and periodic garbage collections are used to migrate memory back from a thread-local cache into the central data structures.
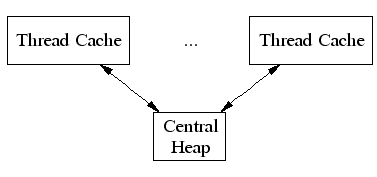
TCMalloc treats objects with size <= 256K ("small" objects) differently from larger objects. Large objects are allocated directly from the central heap using a page-level allocator (a page is a 8K aligned region of memory). I.e., a large object is always page-aligned and occupies an integral number of pages.
A run of pages can be carved up into a sequence of small objects, each equally sized. For example a run of one page (4K) can be carved up into 32 objects of size 128 bytes each.
Small Object Allocation
Each small object size maps to one of approximately 88 allocatable size-classes. For example, all allocations in the range 961 to 1024 bytes are rounded up to 1024. The size-classes are spaced so that small sizes are separated by 8 bytes, larger sizes by 16 bytes, even larger sizes by 32 bytes, and so forth. The maximal spacing is controlled so that not too much space is wasted when an allocation request falls just past the end of a size class and has to be rounded up to the next class.
A thread cache contains a singly linked list of free objects per size-class.
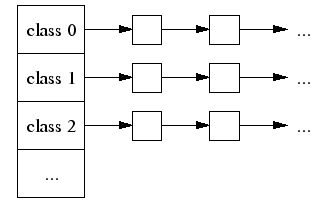
When allocating a small object: (1) We map its size to the corresponding size-class. (2) Look in the corresponding free list in the thread cache for the current thread. (3) If the free list is not empty, we remove the first object from the list and return it. When following this fast path, TCMalloc acquires no locks at all.
If the free list is empty: (1) We fetch a bunch of objects from a central free list for this size-class (the central free list is shared by all threads). (2) Place them in the thread-local free list. (3) Return one of the newly fetched objects to the applications.
If the central free list is also empty: (1) We allocate a run of pages from the central page allocator. (2) Split the run into a set of objects of this size-class. (3) Place the new objects on the central free list. (4) As before, move some of these objects to the thread-local free list.
Sizing Thread Cache Free Lists
It is important to size the thread cache free lists correctly. If the free list is too small, we’ll need to go to the central free list too often. If the free list is too big, we’ll waste memory as objects sit idle in the free list.
Note that the thread caches are just as important for deallocation as they are for allocation. Without a cache, each deallocation would require moving the memory to the central free list. Also, some threads have asymmetric alloc/free behavior (e.g. producer and consumer threads), so sizing the free list correctly gets trickier.
To size the free lists appropriately, we use a slow-start algorithm to determine the maximum length of each individual free list. As the free list is used more frequently, its maximum length grows. However, if a free list is used more for deallocation than allocation, its maximum length will grow only up to a point where the whole list can be efficiently moved to the central free list at once.
The pseudo-code below illustrates this slow-start algorithm. Note that
num_objects_to_move is specific to each size class. By moving a list
of objects with a well-known length, the central cache can efficiently
pass these lists between thread caches. If a thread cache wants fewer
than num_objects_to_move, the operation on the central free list has
linear time complexity. The downside of always using
num_objects_to_move as the number of objects to transfer to and from
the central cache is that it wastes memory in threads that don’t need
all of those objects.
Start each freelist max_length at 1.
Allocation
if freelist empty {
fetch min(max_length, num_objects_to_move) from central list;
if max_length < num_objects_to_move { // slow-start
max_length++;
} else {
max_length += num_objects_to_move;
}
}
Deallocation
if length > max_length {
// Don't try to release num_objects_to_move if we don't have that many.
release min(max_length, num_objects_to_move) objects to central list
if max_length < num_objects_to_move {
// Slow-start up to num_objects_to_move.
max_length++;
} else if max_length > num_objects_to_move {
// If we consistently go over max_length, shrink max_length.
overages++;
if overages > kMaxOverages {
max_length -= num_objects_to_move;
overages = 0;
}
}
}
See also the section on Garbage Collection to
see how it affects the max_length.
Medium Object Allocation
A medium object size (256K ≤ size ≤ 1MB) is rounded up to a page size
(8K) and is handled by a central page heap. The central page heap
includes an array of 128 free lists. The k-th entry is a free list of
runs that consist of k + 1 pages:
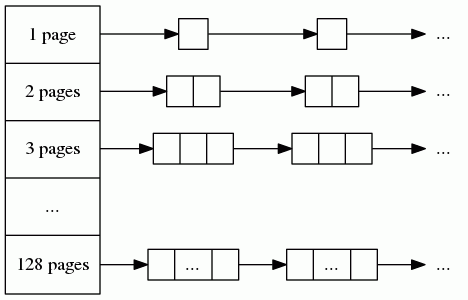
An allocation for k pages is satisfied by looking in the k-th
free list. If that free list is empty, we look in the next free list,
and so forth. If no medium-object free list can satisfy the allocation,
the allocation is treated as a large object.
Large Object Allocation
Allocations of 1MB or more are considered large allocations. Spans of
free memory which can satisfy these allocations are tracked in a
red-black tree sorted by size. Allocations follow the best-fit
algorithm: the tree is searched to find the smallest span of free space
which is larger than the requested allocation. The allocation is carved
out of that span, and the remaining space is reinserted either into the
large object tree or possibly into one of the smaller free-lists as
appropriate. If no span of free memory is located that can fit the
requested allocation, we fetch memory from the system (using sbrk,
or mmap).
If an allocation for k pages is satisfied by a run of pages of
length > k, the remainder of the run is re-inserted back into the
appropriate free list in the page heap.
Spans
The heap managed by TCMalloc consists of a set of pages. A run of
contiguous pages is represented by a Span object. A span can either
be allocated, or free. If free, the span is one of the entries in a
page heap linked-list. If allocated, it is either a large object that
has been handed off to the application, or a run of pages that have been
split up into a sequence of small objects. If split into small objects,
the size-class of the objects is recorded in the span.
A central array indexed by page number can be used to find the span to which a page belongs. For example, span a below occupies 2 pages, span b occupies 1 page, span c occupies 5 pages and span d occupies 3 pages.
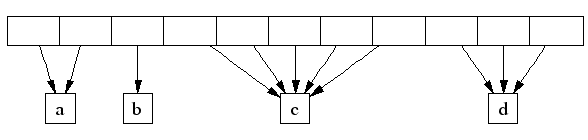
In a 32-bit address space, the central array is represented by a a 2-level radix tree where the root contains 32 entries and each leaf contains 2^14 entries (a 32-bit address space has 2^19 8K pages, and the first level of tree divides the 2^19 pages by 2^5). This leads to a starting memory usage of 64KB of space (2^14*4 bytes) for the central array, which seems acceptable.
On 64-bit machines, we use a 3-level radix tree. Note that, many common 64-bit machines have limits on actual address space size. So on x86 we use 48 bits of address and handle it by slightly-faster 2-level radix tree.
Deallocation
When an object is deallocated, we compute its page number and look it up in the central array to find the corresponding span object. The span tells us whether or not the object is small, and its size-class if it is small. If the object is small, we insert it into the appropriate free list in the current thread’s thread cache. If the thread cache now exceeds it’s max_size_ amount, we run a garbage collector that moves unused objects from the thread cache into central free lists.
If the object is large, the span tells us the range of pages covered by
the object. Suppose this range is [p,q]. We also lookup the spans
for pages p-1 and q+1. If either of these neighboring spans are
free, we coalesce them with the [p,q] span. The resulting span is
inserted into the appropriate free list in the page heap.
Central Free Lists for Small Objects
As mentioned before, we keep a central free list for each size-class. Each central free list is organized as a two-level data structure: a set of spans, and a linked list of free objects per span.
An object is allocated from a central free list by removing the first entry from the linked list of some span. (If all spans have empty linked lists, a suitably sized span is first allocated from the central page heap.)
An object is returned to a central free list by adding it to the linked list of its containing span. If the linked list length now equals the total number of small objects in the span, this span is now completely free and is returned to the page heap.
Garbage Collection of Thread Caches
Garbage collecting objects from a thread cache keeps the size of the
cache under control and returns unused objects to the central free
lists. Some threads need large caches to perform well while others can
get by with little or no cache at all. When a thread cache goes over its
max_size, garbage collection kicks in and then the thread competes
with the other threads for a larger cache.
Garbage collection is run only during a deallocation. We walk over all free lists in the cache and move some number of objects from the free list to the corresponding central list.
The number of objects to be moved from a free list is determined using a
per-list low-water-mark L. L records the minimum length of the
list since the last garbage collection. Note that we could have
shortened the list by L objects at the last garbage collection
without requiring any extra accesses to the central list. We use this
past history as a predictor of future accesses and move L/2 objects
from the thread cache free list to the corresponding central free list.
This algorithm has the nice property that if a thread stops using a
particular size, all objects of that size will quickly move from the
thread cache to the central free list where they can be used by other
threads.
If a thread consistently deallocates more objects of a certain size than
it allocates, this L/2 behavior will cause at least L/2 objects
to always sit in the free list. To avoid wasting memory this way, we
shrink the maximum length of the freelist to converge on
num_objects_to_move (see also
Sizing Thread Cache Free Lists).
Garbage Collection
if (L != 0 && max_length > num_objects_to_move) {
max_length = max(max_length - num_objects_to_move, num_objects_to_move)
}
The fact that the thread cache went over its max_size is an
indication that the thread would benefit from a larger cache. Simply
increasing max_size would use an inordinate amount of memory in
programs that have lots of active threads. Developers can bound the
memory used with the parameter
TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES.
Each thread cache starts with a small max_size (e.g. 64KB) so that
idle threads won’t pre-allocate memory they don’t need. Each time the
cache runs a garbage collection, it will also try to grow its
max_size. If the sum of the thread cache sizes is less than
TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES, max_size grows easily. If
not, thread cache 1 will try to steal from thread cache 2 (picked
round-robin) by decreasing thread cache 2’s max_size. In this way,
threads that are more active will steal memory from other threads more
often than they are have memory stolen from themselves. Mostly idle
threads end up with small caches and active threads end up with big
caches. Note that this stealing can cause the sum of the thread cache
sizes to be greater than TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES until
thread cache 2 deallocates some memory to trigger a garbage
collection.
Performance Notes
gperftools' area of relative strength is cases where per-thread caches are effective. This is typically exercised by fairly typical C++ codes that allocate relatively often and where object lifetimes tend to be small-ish.
Both "abseil tcmalloc" and gperftools continue to have un-sharded central free lists and page heaps. Which means that misses to caches tend to be not so scalable compared to some competition.
This means that in some cases you may want to tweak thread caches
higher. Also if your workload has many threads that tend to be idle
for longer durations, consider using
MallocExtension::MarkThread{Idle,Busy}.
Modifying Runtime Behavior
You can more finely control the behavior of the tcmalloc via environment variables.
Generally useful flags:
|
default: 0 |
The approximate gap between
sampling actions. That is, we take one sample approximately once every
|
|
default: 1.0 |
Rate at which we release
unused memory to the system, via |
|
default: 1073741824 |
Allocations larger than this value cause a stack trace to be dumped to stderr. The threshold for dumping stack traces is increased by a factor of 1.125 every time we print a message so that the threshold automatically goes up by a factor of ~1000 every 60 messages. This bounds the amount of extra logging generated by this flag. Default value of this flag is very large and therefore you should see no extra logging unless the flag is overridden. |
|
default: 33554432 |
Bound on the total amount of bytes allocated to thread caches. This bound is not strict, so it is possible for the cache to go over this bound in certain circumstances. This value defaults to 16MB. For applications with many threads, this may not be a large enough cache, which can affect performance. If you suspect your application is not scaling to many threads due to lock contention in TCMalloc, you can try increasing this value. This may improve performance, at a cost of extra memory use by TCMalloc. See Garbage Collection for more details. |
|
default: false |
Enables "aggressive decommit mode", which makes all tcmalloc to return all free spans to kernel. This reduces total phsycical memory usage at cost of some performance (about 2% cpu hit in Chrome was measured at some point). |
|
default: getpagesize() |
Sometimes we run on systems with larger than anticipatesd hardware page size. I.e. ARMs (and soon RISC-Vs) can run 64k pages mode. We detect actual page size at run-time and adjust our span sizings to do memory management syscalls with correct granularity. Larger pages generally cause somewhat higher memory fragmentation, so we have this parameter to be able measuring fragmentation impact of larger pages. |
|
default: No limit |
Sets limit on total size of page heap (in-use spans and "free but not returned" spans). When tcmalloc hits this limit it tries to return some free spans to kernel. And if that isn’t enough to keep page heap size under limit it OOMs. "abseil tcmalloc" has equivalent "hard limit". |
Advanced "tweaking" flags, that control more precisely how tcmalloc tries to allocate memory from the kernel.
|
default: false |
If true, do not try to use
|
|
default: false |
If true, do not try to use
|
|
default: "" |
If set, specify a path where hugetlbfs or tmpfs is mounted. This may allow for speedier allocations. |
|
default: 0 |
Limit total memfs allocation size to specified number of MB. 0 means "no limit". |
|
default: false |
If true, abort() whenever memfs_malloc fails to satisfy an allocation. |
|
default: false |
If true, ignore failures from mmap. |
|
default: false |
If true, use MAP_PRIVATE when mapping via memfs, not MAP_SHARED. |
|
default: false |
If true, OOM on failing to allocate from memfs instead of falling back to anonymous memory (sbrk/mmap) |
Modifying Behavior In Code
The MallocExtension class, in malloc_extension.h, provides a few
knobs that you can tweak in your program, to affect tcmalloc’s behavior.
Releasing Memory Back to the System
By default, tcmalloc will release no-longer-used memory back to the kernel gradually, over time. The tcmalloc_release_rate flag controls how quickly this happens. You can also force a release at a given point in the progam execution like so:
MallocExtension::instance()->ReleaseFreeMemory();
You can also call SetMemoryReleaseRate() to change the
tcmalloc_release_rate value at runtime, or GetMemoryReleaseRate
to see what the current release rate is.
Memory Introspection
There are several routines for getting a human-readable form of the current memory usage:
MallocExtension::instance()->GetStats(buffer, buffer_length); MallocExtension::instance()->GetHeapSample(&string); MallocExtension::instance()->GetHeapGrowthStacks(&string);
The last two create files in the same format as the heap-profiler, and can be passed as data files to pprof. The first is human-readable and is meant for debugging.
Generic Tcmalloc Status
TCMalloc has support for setting and retrieving arbitrary 'properties':
MallocExtension::instance()->SetNumericProperty(property_name, value); MallocExtension::instance()->GetNumericProperty(property_name, &value);
It is possible for an application to set and get these properties, but
the most useful is when a library sets the properties so the application
can read them. Here are the properties TCMalloc defines; you can access
them with a call like
MallocExtension::instance()→GetNumericProperty("generic.heap_size", &value);:
|
Number of bytes used by the application. This will not typically match the memory use reported by the OS, because it does not include TCMalloc overhead or memory fragmentation. |
|
Bytes of system memory reserved by TCMalloc. |
|
Number of bytes in free, mapped pages in page heap. These bytes can be used to fulfill allocation requests. They always count towards virtual memory usage, and unless the underlying memory is swapped out by the OS, they also count towards physical memory usage. |
|
Number of bytes in free, unmapped pages in page heap. These are bytes that have been released back to the OS, possibly by one of the MallocExtension "Release" calls. They can be used to fulfill allocation requests, but typically incur a page fault. They always count towards virtual memory usage, and depending on the OS, typically do not count towards physical memory usage. |
|
Sum of pageheap_free_bytes and pageheap_unmapped_bytes. Provided for backwards compatibility only. Do not use. |
|
A limit to how much memory TCMalloc dedicates for small objects. Higher numbers trade off more memory use for — in some situations — improved efficiency. |
|
A measure of some of the memory TCMalloc is using (for small objects). |
|
A lower limit to how much memory TCMalloc dedicates for small objects per thread. Note that this property only shows effect if per-thread cache calculated using tcmalloc.max_total_thread_cache_bytes ended up being less than tcmalloc.min_per_thread_cache_bytes. |
Caveats
TCMalloc may be somewhat more memory hungry than other mallocs, (but tends not to have the huge blowups that can happen with other mallocs). In particular, at startup TCMalloc allocates approximately 240KB of internal memory.
Don’t try to load TCMalloc into a running binary (e.g., using JNI in Java programs). The binary will have allocated some objects using the system malloc, and may try to pass them to TCMalloc for deallocation. TCMalloc will not be able to handle such objects.
Original author: Sanjay Ghemawat
Last updated by: Aliaksei Kandratsenka (Dec 2024)